所用软件及环境
- Centos 7
- jdk1.8.0_181
- hadoop-2.9.2
- Hbase-1.4.9
- idea U
注:全程使用root用户
规划
| 组件 | 版本 | 路径 |
|---|---|---|
| jdk | 1.8.0_181 | /usr/local/java |
| Hadoop | 2.9.2 | /usr/local/hadoop |
| Hbase | 1.4.9 | /usr/local/hbase |
| 节点 |
|---|
| node01 |
| node02 |
| node03 |
注:节点IP根据实际情况自行配置
Hadoop、jdk、Hbase下载
下载地址
点击即可下载
配置
1.主机名修改
在node01上输入
hostnamectl --static set-hostname node01
2.添加各个节点的IP
输入:
vim /etc/hosts
添加各个节点信息
<!-- 下列的IP需根据自己的主机确定,不唯一 -->
192.168.130.130 node01
192.168.130.133 node02
192.168.130.135 node03
3.防火墙设置
若主机中未安装iptables,执行以下命令进行安装
yum install iptables-services
执行iptables -L -n -v命令可以查看iptables配置,执行以下命令永久关闭主机的iptables:
chkconfig iptables off
同时关闭主机的iptables和firewalld并设置开机不启动,执行以下命令:
systemctl stop iptables
systemctl disable iptables
systemctl stop firewalld
systemctl disable firewalld
执行systemctl status iptables和systemctl status firewalld可以查看防火墙已经关闭。
4.时钟同步
执行以下命令安装ntdate
yum install ntpdate
执行以下命令同步时针
ntpdate us.pool.ntp.org
添加时针同步的定时任务,执行以下命令
crontab -e
接着输入以下内容,设置每天凌晨5点同步时针
0 5 * * * /usr/sbin/ntpdate cn.pool.ntp.org
执行以下命令重启服务并设置开机自启:
service crond restart
systemctl enable crond.service
5.SSH免密登录
首先执行以下以下命令,可以生成.ssh隐藏文件夹
ssh localhost
接着执行
cd .ssh
ssh-keygen -t rsa #遇到提示一路回车就行
ll #会看到 id_rsa id_rsa.pub 两文件前为私钥,后为公钥
cat id_rsa.pub >> authorized_keys #把公钥内容追加到authorized_keys文件中
chmod 600 authorized_keys #修改文件权限,重要不要忽略
在最后的克隆node01得到的node02,node03主机以及node01上可通过ssh node01/node02/node03/node04测试是否可以免密登录
若能连接即为成功
6.安装并配置jdk
通过 git 将已下载好的jdk1.8.0_181 发送给各个节点,执行以下命令
cd C:/Users//Yan/Downloads #C:/Users//Yan/Downloads为本人jdk1.8.0_181下载后的路径
scp jdk1.8.0_181 root@192.168.130.130:/usr/local/java #输入密码后即可将jdk1.8.0_181发送给node01,192.168.130.130为自己node01的IP
cd /usr/local/java进入该目录后执行
tar -zxvf jdk-8u181-linux-x64.tar.gz
添加环境变量,执行
vim /etc/profile
添加以下配置
export JAVA_HOME=/usr/local/java/jdk1.8.0_181
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=.:$JAVA_HOME/bin:$PATH
之后执行以下命令使配置生效
source /etc/profile
可通过 java -version 查看jdk版本
安装 Hadoop 并配置
执行以下命令
cd /usr/local/hadoop
tar -zxvf hadoop-2.9.2.tar.gz #解压
添加环境变量,执行
vim /etc/profile
在该文件中添加以下内容
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行 source /etc/profile 使配置生效
同时创建Hadoop相关配置目录
mkdir -p /data/hadoop/hdfs/name /data/hadoop/hdfs/data /var/log/hadoop/tmp
修改相关文件
执行以下命令
cd /usr/local/hadoop/hadoop-2.9.2/etc/hadoop
hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_181 #一定要写真实路径
core-site.xml
<configuration>
<!-- define the default file system host and port -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000/</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- set namenode storage path-->
<!-- storage node info -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///root/hdfs/namenode</value>
<description>NameNode directory for namespace and transaction logs storage.</description>
</property>
<!-- set datanode storage path-->
<!-- storage data -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///root/hdfs/datanode</value>
<description>DataNode directory</description>
</property>
<!-- set the number of copies, default 3, reset to 2 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<!-- specify the frame name -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
slaves
node02
node03
node04
yarn-site.xml
<configuration>
<!-- Ancillary services running on the NodeManager. You need to configure "mapreduce_shuffle" to run the MapReduce program. -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- The class corresponding to the auxiliary service in the NodeManager. -->
<!-- <property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property> -->
<!-- Configuration name node -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
</configuration>
启动 Hadoop
初始化
执行以下命令
cd /usr/local/hadoop/hadoop-2.9.2/bin
./hdfs namenode -format
等待一会后,不报错返回 “Exiting with status 0” 为成功,“Exiting with status 1”为失败
切勿多次执行
克隆
对node01进行克隆操作进而得到node02,node03,node04
修改node02,node03,node04的主机名,以及检查/etc/hosts文件中的各个节点对应的IP地址是否有误
同时也要检查自己配置的/etc/profile文件是否已经生效
启动Hadoop
输入以下命令
sudo -s #若是root用户可省略
cd /usr/local/hadoop/hadoop-2.9.2/sbin
./start-all.sh
查看Hadoop进程
输入命令jps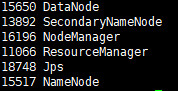
若出现6个进程则为配置正确
在浏览器输入192.168.130.130:8088则可以看到
在浏览器输入192.168.130.130:50070则可以看到
即配置成功
停止Hadoop
./stop-all.sh #在/usr/local/hadoop/hadoop-2.9.2/sbin目录下
安装 Hbase 并配置
执行以下命令
cd /usr/local/hbase/
<!-- 解压 -->
tar -zxvf hbase-1.4.9-bin.tar.gz
<!-- 创建目录 -->
cd hbase-1.4.9/
mkdir logs
mkdir pids
mkdir tmp
配置
/etc/profile
export HBASE_HOME=/usr/local/hbasehbase-1.4.9
export PATH=$HBASE_HOME/bin:$PATH
source /etc/profile #使配置立即生效
hbase-env.sh
#内容
export JAVA_HOME=/usr/local/java/jdk1.8.0_181
export HBASE_CLASSPATH=/usr/local/hbase/hbase-1.4.9/conf
# 此配置信息,设置由hbase自己管理zookeeper,不需要单独的zookeeper。
export HBASE_MANAGES_ZK=true
export HBASE_HOME=/usr/local/hbase/hbase-1.4.9
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.9.2
#Hbase日志目录
export HBASE_LOG_DIR=/usr/local/hbase/hbase-1.4.9/logs
hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://node01:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master</name>
<value>node01:60000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
</configuration>
regionservers
node01
node02
node03
拷贝给其他节点
scp -r /usr/local/hbase root@node02:/usr/local/
scp -r /usr/local/hbase root@node03:/usr/local/
启动HBase
在node01上启动
执行
cd /usr/local/hbase/hbase-1.4.9/bin
./start-hbase.sh
验证
在每个节点使用jps命令查看
node01上是否有HMaster进程
node02,node03上是否有HRegionServer进程
通过node:16010查看HBase集群相关情况,如下图所示:
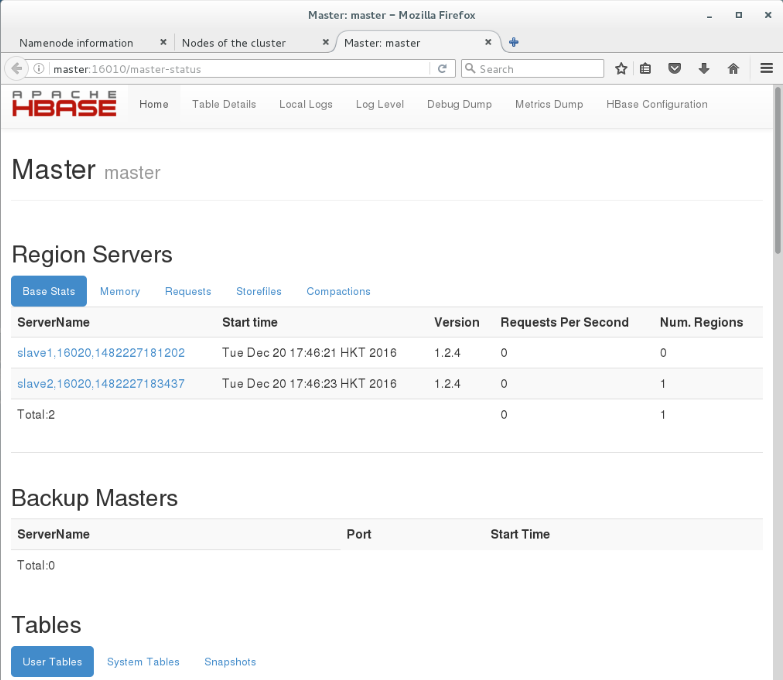
500 为初始化,稍等即可
wordcount
输入以下命令(root用户下)
cd /home/hadoop #hadoop为自己创建的用户名,不固定
touch README.txt
vim README.txt
#下面为README.txt的内容
hello c
hello java
hello python
hadoop fs -mkdir /wordcount
hadoop fs -mkdir /wordcount/input
hadoop fs -put /home/hadoop/README.txt /wordcount/input
cd /usr/local/hadoop/hadoop-2.9.2/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-2.9.2.jar wordcount /wordcount/input /wordcount/output
出现以下信息即为成功:
2018-12-29 20:38:15,997 INFO mapreduce.Job: map 100% reduce 0%
2018-12-29 20:38:24,174 INFO mapreduce.Job: map 100% reduce 100%
2018-12-29 20:38:28,259 INFO mapreduce.Job: Job job_1546086772385_0001 completed successfully
2018-12-29 20:38:29,164 INFO mapreduce.Job: Counters: 55
File System Counters
FILE: Number of bytes read=50
FILE: Number of bytes written=429541
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=144
HDFS: Number of bytes written=28
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Failed map tasks=3
Launched map tasks=4
Launched reduce tasks=1
Other local map tasks=3
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=38093
Total time spent by all reduces in occupied slots (ms)=5732
Total time spent by all map tasks (ms)=38093
Total time spent by all reduce tasks (ms)=5732
Total vcore-milliseconds taken by all map tasks=38093
Total vcore-milliseconds taken by all reduce tasks=5732
Total megabyte-milliseconds taken by all map tasks=39007232
Total megabyte-milliseconds taken by all reduce tasks=5869568
Map-Reduce Framework
Map input records=5
Map output records=6
Map output bytes=56
Map output materialized bytes=50
Input split bytes=110
Combine input records=6
Combine output records=4
Reduce input groups=4
Reduce shuffle bytes=50
Reduce input records=4
Reduce output records=4
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=152
CPU time spent (ms)=2050
Physical memory (bytes) snapshot=517804032
Virtual memory (bytes) snapshot=5624598528
Total committed heap usage (bytes)=336592896
Peak Map Physical memory (bytes)=293904384
Peak Map Virtual memory (bytes)=2790219776
Peak Reduce Physical memory (bytes)=223899648
Peak Reduce Virtual memory (bytes)=2834378752
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=34
File Output Format Counters
Bytes Written=28
查看统计结果
hdfs dfs -ls /wordcount/output
hdfs dfs -cat /wordcount/output/part-r-00000
MapReduce编程
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hadoop</groupId>
<artifactId>wordcount</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
src/main/java/WordcountMapper.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Created by zxk on 2017/6/29.
*/
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//得到输入的每一行数据
String line = value.toString();
//通过空格分隔
String[] words = line.split(" ");
//循环遍历输出
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
src/main/java/WordcountReducer.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Created by zxk on 2017/6/29.
*/
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
Integer count = 0;
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
src/main/java/WordCountMapReduce.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* Created by zxk on 2017/6/29.
*/
public class WordCountMapReduce {
public static void main(String[] args) throws Exception {
//创建配置对象
Configuration conf = new Configuration();
//创建job对象
Job job = Job.getInstance(conf, "wordcount");
//设置运行job的类
job.setJarByClass(WordCountMapReduce.class);
//设置mapper 类
job.setMapperClass(WordcountMapper.class);
//设置reduce 类
job.setReducerClass(WordcountReducer.class);
//设置map输出的key value
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce 输出的 key value
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入输出的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交job
boolean b = job.waitForCompletion(true);
if (!b) {
System.out.println("wordcount task fail!");
}
}
}
编译打包
在idea中打jar包可以参考这里 点击
运行
<!-- 一些命令与worcount命令相同不再重复 -->
hadoop jar hadoop-demo.jar WordCountMapReduce /wordcount/input /wordcount/output
参考
在centos7上搭建hadoop集群
CentOS 7搭建Apache Hadoop 3.1.1集群
Linux上安装Hadoop集群(CentOS7+hadoop-2.8.0)
Centos7虚拟机 搭建 Hadoop3.1.1 教程
CentOS 7下安装集群HBase1.2.4
windows下idea编写WordCount程序,并打jar包上传到hadoop集群运行
